
Why AI Engineering Isn't About the Models
Why the unglamorous infrastructure beats the smartest models

Building with AI has always felt like trying to conduct an orchestra where the musicians speak different languages. We obsess over model capabilities, benchmark scores, and parameter counts. But after listening to Greg Brockman discuss Codex on the OpenAI podcast, something clicked: the real work for engineers isn't in the model. It’s the harness around it.
The harness is everything that happens before the prompt and after the response. It's the unglamorous plumbing that transforms raw capability into actual utility. And right now, most of us are barely scratching the surface.
What makes a harness?
The AI is just the engine. The harness is everything else: the transmission, the steering, the dashboard, and especially the feedback loops.
Look at any successful AI implementation and you'll find the same pattern:
Input preparation: Getting data into the right shape, context window management, prompt engineering, retrieval systems.
Output processing: Parsing responses, validation, error handling, integration with existing systems.
Feedback loops: Runtime errors, test results, user corrections, performance metrics flowing back to improve the next iteration.
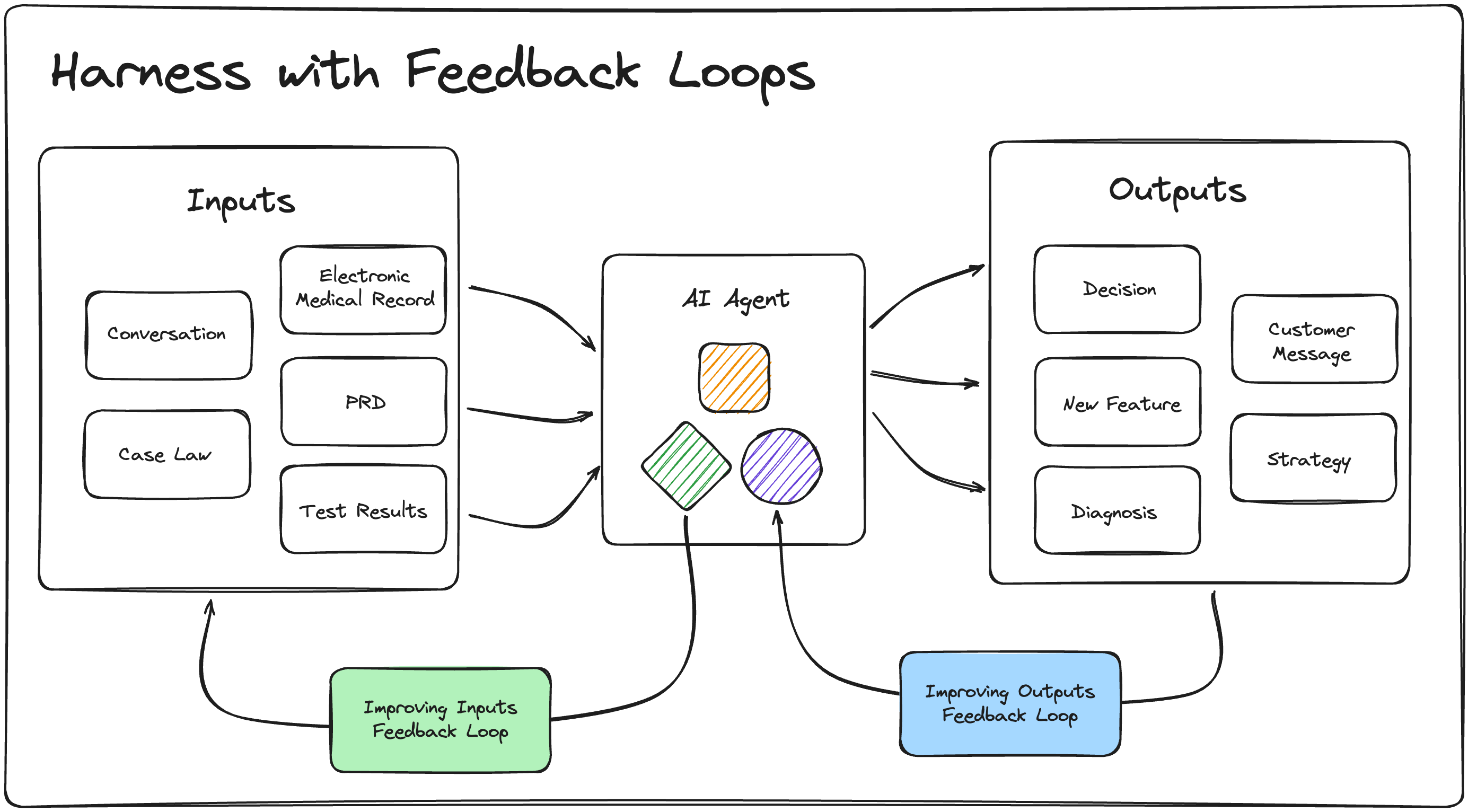
Apologies for my crappy drawing. Two things to note: the agent searches over inputs to build context, and it searches over inner-loop outputs. The harness is the whole thing.
Take AI software engineers like Devin. The model generates code, sure. But the harness is what makes it useful:
File system access for reading and writing code
Runtime integration across languages and stacks
Console output capture and error parsing
LSP results and test failure analysis
All of it feeding back into the next generation attempt
This is where companies like Qodo have found an edge. They didn't chase better embeddings or fancier vector databases. They built advanced regex patterns for searching codebases, APIs, and documentation. Old school? Maybe. Effective? Absolutely.
The billion-dollar pattern
Three industries are sitting on the edge of transformation, and it's not because the models just got good enough. It’s back to Richard Sutton’s Bitter Lesson. AI does better with search and learning (I think there’s one he forgot, I’ll mention later)
The harnesses for Customer Experience, Legal and Healthcare are already built or nearly so. In a broad sense, these industries have already gone through a few tech revolutions already with digitization, the move to cloud and then SaaS takeover. This poised them for the next disruption.
Why these three? From a technology point of view, they share a specific challenge profile:
Broad search requirements. Differential diagnoses, case law review, customer intent matching across thousands of scenarios.
Deep analysis needs. Finding every positive and negative predictor, every precedent, every edge case that matters for this specific situation.
Expertise bottlenecks. There simply aren't enough qualified professionals. The knowledge required spans both breadth and depth in ways that limit the talent pool.
High-value outcomes. When a lawyer bills $800/hour or a specialist charges $500 for a 15-minute consultation, shaving even 20% off task time saves billions annually. Per country. Per jurisdiction. Per healthcare system.
The harness advantage
These domains aren't just ripe for disruption because the problems are hard. They're ready because the harness patterns have been incubating:
Structured data flows: Medical records, legal documents, customer tickets all follow predictable schemas. Unlike general web data, we know what to expect.
Clear success metrics: Did the diagnosis match? Did we find the relevant precedent? Was the customer issue resolved?
Existing tooling to integrate: EMR systems, legal databases, CRM platforms. The infrastructure exists; we just need to wire it up.
Regulatory frameworks: Counterintuitively, heavy regulation helps. It creates standardization and clear requirements for what the harness must do.
I look at this list and think “no big deal”. These are known knowns, we’ve got this.
Building the right abstractions
The software engineering harness gives us a template, but other domains need different primitives. The thing to take here is define the primitives in your domain and keep close to them.
Software Engineering
- File system access
- Runtime execution
- Test frameworks
- Version control
Healthcare
- Patient history retrieval
- Lab result parsing
- Drug interaction checking
- Clinical guideline matching
Legal
- Case law search
- Document comparison
- Citation validation
- Jurisdiction filtering
Customer Experience
- Intent classification
- Conversation history
- System integration
- Workflow automationEach domain needs its own "console" and "file system" equivalents. The winners won't be whoever has the best model, those will keep improving. They'll be whoever builds the most elegant harness. (Sometimes elegance is very, very simple)
But defining primitives and the ability to search them is only half the equation. There’s something else happening when these harnesses work well.
A third force: exposure → learning
Richard Sutton’s Bitter Lesson says progress comes from search and learning. I think there’s a third, practical force at play: exposure.
Here’s my theory: Better search doesn’t just find information, it exposes unexpected connections. When our harness surfaces a customer’s purchase history alongside their support ticket, the agent suddenly “sees” that this is a VIP having their third issue this month. Context that completely changes how to respond. The search exposed a pattern neither human nor model thought to look for.
In engineering terms, this is like the N+1 problem or traversing graph edges. Except here, we actually want the extra lookups.
I call this dynamic learning, not learning in the sense of updating model weights, but in finding the right context for each specific problem while filtering out the noise. It’s like each finding teaches the system what matters right now, not what matters in general.
AI agents are already better at this contextual discovery than I am. They’ll check that thyroid level from three years ago. They’ll notice the correlation between “worried about” and churn risk. They surface connections I’d never think to explore because I’m limited by attention. (Maybe attention is in fact all you need)
So my job isn’t to worship models. My job is to give agents the right primitives and pose the right problems.
This might be totally wrong. Maybe I’m just rediscovering information retrieval with extra steps. Tell me where my thinking breaks down.
Early lessons from the trenches
Working with XtendOps on customer experience automation, patterns are starting to crystallize:
Retrieval beats generation. Having the right context matters more than having a smarter model. Our best improvements came from better search, not bigger models.
Feedback loops compound. Every resolved ticket teaches the system. Every failed automation improves the next attempt. The harness that captures and uses this signal wins.
Domain primitives matter. Generic tools fail. Success requires deep integration with industry-specific systems, formats, and workflows.
Speed introduces new bottlenecks. When AI handles the routine work instantly, review and validation become the constraint. The harness must account for this and longer term it should shift human workflow patterns.
Where we go from here
The next decade won't be about better models, I mean it will, but not just about them. It'll be about better harnesses. The companies that win will be the ones that understand their domain's specific needs and build the infrastructure to support them.
The models are good enough already to have a significant impact in every industry. The question is: who's going to build the harness? where?
I buried the video at the bottom. Apologies 🙏
The harness is where engineering meets domain expertise. It's not sexy. It's not what gets headlines. But it's what actually ships value. And right now, it's wide open.