
When Can You Run Claude Code Overnight, On Your Own Hardware?
Model compression, hardware economics, and the 12-month lag

Every night around midnight I kick off parallel Claude Code agents against acceptance criteria files. By 7am there’s a PR waiting. Sometimes three. The model does the work while I sleep, and most mornings the output is reviewable, not a mess to triage.
It costs money. API tokens, rate limits, a model that could change under my feet tomorrow. And the nagging question I keep coming back to: when does this run on hardware I own, with weights I control, at the same quality?
Not “close enough for chat.” Close enough to trust unattended overnight.
The Confidence Problem
This is a reliability question, not an intelligence question.
Running an agent overnight means you need nines. Not five-nines like an SLA. But enough that across 40 files touched in an overnight run, you don’t wake up to hallucinated imports and broken builds. If the model gets an import wrong 3% of the time, the math kills you fast at scale.

Today’s best local coding models (DeepSeek-R1-Distill-Qwen-32B, Qwen 2.5 Coder 32B) are genuinely good. They beat GPT-4o on coding benchmarks. On a Mac Mini M4 Pro with 64GB ($2,200), they run at 10-15 tok/s at Q4 quantization. Useful for interactive coding. Not the same as trusting them to chew through an acceptance criteria file unsupervised.
The LMArena Coding Arena tells the story:
Claude Opus 4.5 (thinking): ~1538 ELO
Claude Sonnet 4.5 (thinking): ~1524 ELO
Best open models: ~1443-1460 ELO
That’s a 78-95 point spread. The total range from #1 to #60 on the entire coding leaderboard shows the open models aren’t at the back of the pack. They’re a tier below the tier you need for overnight reliability.
Four Trends That Compound
The gap isn’t static. Four forces are compressing it simultaneously, and they multiply.
1. Model compression
Capability per parameter doubles roughly every 3.5 months (Nature Machine Intelligence’s “Densing Law”). The same quality keeps fitting into smaller models. A 32B model today matches what a 70B did 6-9 months ago. MoE architectures accelerate this: DeepSeek V3’s 671B total activates only 37B per token.
2. Hardware economics
A Mac Mini M4 Pro 64GB is $2,200. Two of them clustered with a $50 Thunderbolt 5 cable gives you 128GB unified memory, enough to run 70B models at 8-30 tok/s. Apple recently added RDMA over Thunderbolt 5, so two machines behave like one GPU with shared memory. M5 chips are coming with 512GB rumored. NVIDIA isn’t focused on consumer GPUs. Apple kept pricing flat. The memory-per-dollar curve favors consumer hardware.
3. Inference optimization
Consumer hardware is memory-bandwidth bound, not compute bound. But inference for coding agents is mostly decode-heavy (token generation), which is exactly what this hardware does well. Better quantization methods like Q4_K_M barely degrade math benchmarks on larger models. The software stack (Ollama, MLX, distributed inference tools) works out of the box now. A year ago it didn’t.
4. Harness maturity
This is the one people undercount. The orchestration layer (skills, cron jobs, memory, tool use, self-optimization) is what turns a model into a worker. OpenClaw is open source and already runs on local infrastructure. These harnesses are model-agnostic. When the local model catches up in capability, the scaffolding is ready and waiting.
These four don’t add. They multiply. Better compression means existing hardware runs better models. Cheaper hardware means you cluster for the bigger ones. Better inference means the same cluster runs faster. Better harnesses mean you need less raw model capability because the scaffolding handles more of the orchestration.
The Timeline
Epoch AI found that anyone with a top-end consumer GPU can locally run models matching frontier performance from 6-12 months prior. That lag has compressed significantly over the past two years.
On a single Mac Mini M4 Pro 64GB ($2,200):
When Best local 32B coding model Equivalent to Now (Feb 2026) Beats GPT-4o coding ~18 months behind frontier Aug 2026 ~GPT-5.1 level ~9-12 months behind Feb 2027 ~Opus 4.5 / Gemini 3 Pro level ~6-12 months behind
On a 2-machine cluster (128GB, ~$4,400): shift each row forward 3-6 months.
The coding-specific wrinkle: the coding ELO gap is narrower than general capability, but Claude’s lead has been stickier. Coding rewards precision. Quantization hurts structured output more than chat. A Q4 70B beats full-precision 32B on general reasoning, but for code generation the smaller model at full precision can win on schema-strict tasks. The coding gap will likely close in steps tied to specific model releases, not smoothly.
Catalysts:
DeepSeek V4 (expected any day now). If the distills are good, the 32B could jump the timeline by 3-6 months.
Kimi K2.5 distills. If Moonshot ships small variants, the local coding story changes fast.
M5 silicon. 512GB unified memory. The “what fits” table gets rewritten.
What This Actually Changes
This matters beyond saving on API costs. An overnight agent on local hardware means: no token limits, no rate limits, no model changes under your feet, no data leaving your network.
It means sovereignty. Not privacy in the “I’m hiding something” sense. Control in the “my workflows don’t break because a provider shipped a new version on Tuesday” sense.
For the kind of work I’m doing now, parallel agents against acceptance criteria with progress logging, the local equivalent is a small cluster, an open 70B+ model, an OpenClaw-style harness, and cron jobs kicking off builds at midnight. Factory floor running third shift.
We’re 12-18 months from that being practical at Opus 4.5 coding quality on $4,400 of hardware. Probably 6-9 months from “good enough for most overnight tasks.”
The Economics
The API cost question depends entirely on which model you’re running overnight and how hard you push it.
Opus 4.5 pricing: $5 input / $25 output per million tokens. (Anthropic cut Opus pricing by 66% with the 4.5 release. If you’re still on Opus 4.1 at $15/$75, the local hardware case is a lot stronger.)
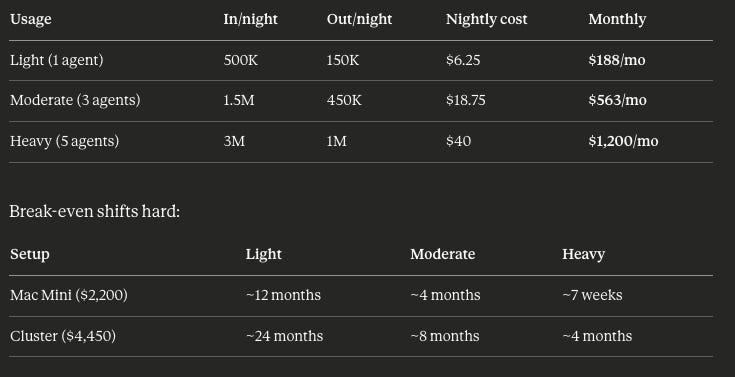
A year ago, the money case for local hardware was obvious. Anthropic (and OpenAI, and Google) have been cutting prices faster than Moore’s Law. At current Opus 4.5 rates, you need to be running heavy overnight workloads before the hardware pays for itself quickly. Light usage? The API is cheap enough that local inference is a convenience play, not an economics play.
But pricing trends cut both ways. Today’s rates assume competition stays fierce and inference keeps getting cheaper. If you’re planning for 12-18 months out, locking in hardware at today’s prices hedges against a world where the race to zero slows down.
The Supply Problem
Here’s what nobody’s talking about: the hardware you’ll want in 12 months is getting bought now.
Every OpenClaw build, every enthusiast stacking Mac Minis, every startup clustering consumer hardware for local inference is competing for the same 64GB and 128GB Apple Silicon machines. Apple doesn’t overproduce. The M5 with 512GB will have allocation constraints at launch. NVIDIA’s consumer GPUs are already supply-limited because the data center business gets priority on wafer allocation.
When open source models cross the overnight-reliability threshold (12-18 months for Opus-tier coding), the people who already have hardware will start running. The people who don’t will be ordering into a backlog.
Memory chips are the bottleneck. HBM demand from data centers is pulling supply away from consumer hardware. DRAM pricing is rising. The $2,200 Mac Mini with 64GB unified memory is cheap right now because Apple locked in favorable memory contracts. That pricing isn’t guaranteed to hold.
The practical path is what it’s always been with hardware bets: buy what’s useful today, and make sure it’s independently valuable if you change direction. A Mac Mini is a dev machine, a server, a build box. Two of them clustered run local inference and everything else. Nothing wasted.
If you’re going to want local inference in a year, the time to buy the hardware is before everyone else figures out the same math.
What I’m Doing About It
Nothing yet. API harnesses are too good right now. Claude Code with Opus 4.6 is the benchmark, Codex with GPT-5.2 close behind. The quality gap means switching today would be a downgrade.
But I’m watching:
DeepSeek V4 distill benchmarks. If a 32B distill lands within 30 ELO of Opus on coding, the math changes.
M5 pricing. If 512GB stays under $5K, a single machine runs anything.
Harness security. The prompt injection problem in agentic local systems is real and unsolved. An overnight agent with internet access and no good way to distinguish trusted from untrusted tokens isn’t just a reliability problem. It’s a security problem.
The convergence is real. The four trends are compounding. The question isn’t if you’ll be able to run frontier coding agents locally overnight. It’s whether your harness is ready when the models arrive.