
The AI Goalie: From 2,000 Daily Errors to 6 Real Issues
Augmenting Goalie work with Claude Code and GitHub Issues

Last Tuesday, our monitoring dashboard showed 1,847 errors across 275k serverless function invocations. After two hours of manual triage, we'd identified six actual problems. The other 1,841 errors? Variations on the same themes, duplicate stack traces with different timestamps, and timeout cascades from those six root causes.
We were drowning in noise while the signal screamed for attention.
The Error Noise Problem
Dealing with roughly 2,000 errors per day flooding our error tracking system is no small task. There are really only a handful of actual root causes. Yes, we're aware of them. 😅
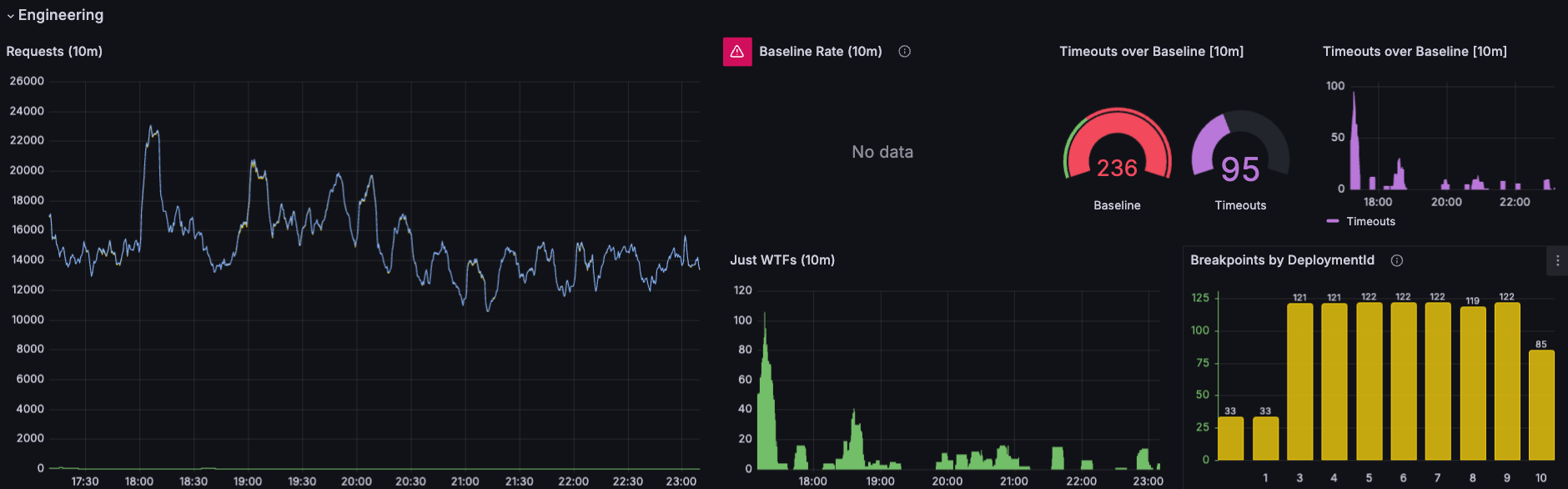
But awareness and action are different beasts. Tracing spikes in timeouts with their related calls is time-consuming work. When a timeout in Service A triggers retries in Service B, which overwhelms Service C, you get a cascade of errors that all look unique to traditional clustering algorithms. Each one gets its own alert, its own ticket, its own investigation thread.
The Goalie role emerged from this chaos: the first line of defense whose job is to catch, sort, and route these errors before they hit the broader team. But our Goalies were burning out on repetitive triage, spending more time categorizing noise than investigating actual issues.
Traditional clustering treats timestamped retries as unique, so a timeout in A → retries in B → saturation in C looks like dozens of “different” failures. Our Goalie (first-line triage) was spending hours labeling noise instead of investigating root causes. We needed grouping by cause, not string equality.
Attempt 1: Building a Dedicated Management App (The Engineer-First Trap)
My first instinct was to build our way out. We created a custom error management application with the engineer in mind. Clean UI, purpose-built for our workflow, with all the features we thought we needed.
What we built:
Custom triage interface with keyboard shortcuts and bulk actions
HITL (Human In The Loop) workflow for review and approval
Built-in suppression rules and custom filtering
Dashboard for tracking error trends over time
The good news? Triage looked easier. Engineers could suppress known issues, add custom tags, and build domain-specific features as needed. The suppressions alone cut out about 20% of the noise.
Throughout, I mention Claude Code. You may substitute any of your favorite agentic systems: Codex, Devin, etc.
But we hit a wall when we tried to make it smarter. We wanted Issues pre-filled with app-specific context (repro steps, related logs, owners, and links). Research takes time. The app still needed to translate everything into an environment where Claude Code could operate: repository access, MCP tools, ability to output Ephemeral Data markdown, JSON, and log files. Not to mention, we were maintaining overhead for another application in our SDLC, adding deployment pipelines, monitoring, and updates.
The real insight came when we stepped back and looked at what we'd built. The UI was optimized for engineers, not for AI consumption. Meanwhile, GitHub already had 90% of the features we needed: issue tracking, assignment, labels, comments, history. It just lacked the intelligent clustering database.
Not to mention, without Claude Code properly integrated into the loop, our clustering algorithm remained chatty. Roughly an 80% reduction as seen above is still a lot for a small team. We'd essentially built a prettier version of the same problem.
Attempt 2: App + Claude Code Fingerprinting (The Expensive Middle Ground)
Instead of scrapping everything, we tried to augment the UI. Keep the app but add Claude Code for smarter fingerprinting. Use deterministic code for fast, cheap clustering, then enhance with AI.
The trade-offs became clear quickly. Our code-based clustering wasn't codebase context-aware. It couldn't look at a stack trace and understand that connection_timeout in an integration endpoint and status=500 END in the same endpoint were the same underlying integration issue. We wanted a richer experience, otherwise we would just use the tools we had.
We got Claude Code working through a GitHub Workflow, but the economics didn't work. Running it every 30 minutes would cost us $600 per month. Not huge for some teams, but non-trivial for a process improvement without dedicated budget. (Getting budget approval for "we want to pay AI to look at our errors" is another story entirely.)
To top it off, the approach was still brittle. We would need frequent HITL updates to the rulesets. The connection between the UI and Runtime in GH Actions was tenuous. New error patterns would often require manual intervention. The app had become a thin wrapper that wasn't doing much beyond what we could get from existing tools.
The realization: Claude Code was doing all the real work anyway. Why were we maintaining infrastructure around it?
Attempt 3: Claude Code as Orchestrator (The Sweet Spot)
We flipped the architecture. Instead of Claude Code as an add-on, it became the main driver. Run it in GitHub Actions or locally during development. Use ephemeral data processing: collect the last 30 minutes of errors, cluster them, compare to existing GitHub issues, update accordingly.
The approach is deceptively simple:
Collect recent errors from our monitoring tools
First pass: tool-based clustering using traditional methods 100% → 20%
Second pass: Claude Code reads the clusters and applies intelligent grouping 20% → ~2%
Match against existing GitHub issues or create new ones
Enrich with Issues further
Find other related
infologs associated with the requestCodebase awareness with the Root Cause Analysis
Web Researcher for identifying external dependency causes
Architecture review for persistent Issues
The results shocked us. Our code-based clustering would identify 42 distinct error groups from a typical 30-minute window. Claude Code reduces this to 6 actual issues. It properly identifies which GitHub issues to attach new errors to, even when the error messages are completely different.
What makes this work is how Claude Code approaches the problem. According to Promptlayer's analysis, it's built more on advanced regex patterns than pure semantic similarity. This turns out to be perfect for error clustering, where you need to recognize that /api/users/123/profile and /api/users/456/profile are the same pattern with different parameters.
Claude Code can also reference older, closed issues for pattern matching. "This looks like issue #1234 from last month" becomes actionable intelligence rather than tribal knowledge.
The Tool Chain That Makes It Work
Our current stack is deliberately simple:
MCP tools + custom CLI tools for data collection (yes, could be MCP-only, but you know how it is)
GitHub Issues as both database and UI (already there, already familiar, already integrated)
Claude Code managing the runtime and orchestration
Ephemeral processing: No state management, no database, no synchronization issues
The beauty is in what we didn't build. No custom UI to maintain. No database to back up. No deployment pipeline to monitor. Just Claude Code reading errors and updating GitHub issues either locally in development or in GH Actions.
A typical run looks like this:
# Claude Code Command: Error Goalie
## Role
You are an error tracking specialist who fetches production errors and manages GitHub issues.
Run the entire error tracking pipeline locally, replacing costly cloud workflows.
## Pipeline
### 0. Defaults
- N Minutes = 30
### 1. Fetch & Process Errors
- Use the `tools/error-tracking` to pull errors
- Pull errors from monitoring service (last N minutes)
- Generate fingerprinted error files (issue-*.md)
- Each file contains clustered errors with same root cause
### 2. Get Existing Issues
- Fetch all open GitHub issues
- Extract fingerprints and error patterns from issue bodies
### 3. Intelligent Deduplication
Group errors when they have:
- Same fingerprint or >80% similarity
- Same error type and service
- Related stack traces (same root cause)
### 4. Issue Management
**Update existing issues when:**
- Same fingerprint exists
- Similar error pattern detected
- Add comment with new occurrences
- Escalate severity if velocity increases
**Create new issues when:**
- No matching fingerprint found
- Different service or error type
- Apply severity labels based on impact:
- critical: >100/hour, auth failures, 500s
- high: >50/hour, core features
- medium: 10-50/hour, degraded UX
- low: <10/hour, non-critical
### 5. Execute GitHub Operations
```bash
# Create issue
gh issue create --title "[Service]: Error" --body "..." --label "severity:high"
# Update issue
gh issue comment NUMBER --body "New occurrences: X in last hour"Ours naturally has more to it, I abbreviated it for the post, but please reach out if you would like me to detail it further.
The feedback loop is built in. When an engineer corrects a clustering decision (moving an error to a different issue), it is documented in GitHub Issues and that will feed back into the system for the future.
Early Results & What's Next
The numbers so far:
42 code-based clusters → 6 real issues on an average run
Goalie time on triage: Down from 2 hours to 15 minutes per shift freeing up Implementation time
We're still measuring the impact on actual resolution time. It's a moving target since we're scaling our services simultaneously, but early indicators are positive. Engineers report spending less time figuring out what's wrong and more time fixing it.
The next experiment is autonomous fixes. We will identify what percentage of issues Claude Code could theoretically solve completely.
We’re thinking:
Issue → Research → Plan → Implement
With HITL approval at the Plan stage. Both Research and Plan accuracy are critical gates. If Claude Code can correctly identify the problem and propose a valid solution, implementation is often straightforward.
Early tests suggest about 30% of our errors could be auto-fixed: configuration updates, retry logic adjustments, timeout increases. The kind of fixes that are obvious once you understand the problem but time-consuming to track down.
The Reality Check
This isn't a silver bullet. Some challenges remain:
What still needs human creativity:
Novel error patterns we haven't seen before
Complex business logic issues
Architectural decisions about scaling or redesign
The learning curve:
Initial setup requires good examples of proper clustering and is highly specific to your codebase
You need to correct it when it's wrong (and it will be wrong)
Agentic coding requires a shift in the Human Engineers mindset
Closing Thoughts
The best infrastructure is the one suited to you and your process. By letting GitHub handle the UI and Claude Code handle the intelligence, we finally built process that actually reduces the work burden for our weekly Goalie.
I haven’t found a better way of doing this other than building it yourself, iterating through the process and finding what doesn’t work for you. It highlights a broader change in how we approach engineering problems. As an industry, we need to be smart about where we combine people and processes with AI. Every purchasing decision now has an underlying question, “Can we do it ourself?”
Our error rate hasn't changed drastically yet (still working on that), but our response to those errors is transforming. The Goalie role evolved from a burden to be rotated to a strategic position that actually improves our systems.
Next up: We're experimenting with letting Claude Code suggest architectural improvements based on error patterns. If certain types of errors keep recurring, maybe the problem isn't the error handling but the architecture itself.
But that's a post for another day. For now, we're just happy our Goalies can actually play defense instead of drowning in noise.
Please reach out to me if you want to discuss!