
Orchestrate to Survive the Speed
The factory floor is uncomfortable

I’ve been running 3-5 Claude Code instances in parallel for months. They’re all productive. They’re all stuck waiting on me.
The speed isn’t the problem. The speed is almost too easy to get. The problem is surviving it.
A few months back I wrote about orchestrator architectures. That was about how single coding agents are internally orchestrating their workflows. I see new patterns emerging for coordinating multiple coding agents.
Which terminal had the auth refactor? Did I review that PR from the logging agent? The one working on the API schema, did it ever get unstuck? You become the bottleneck. Not because you’re slow, but because you’re the only thing holding the state of five parallel workstreams in your head.
It’s time for tools that assist you in handling multiple agent sessions. You orchestrate not to go faster. You orchestrate to survive the speed.
Several tools are converging on this problem. Steve Yegge’s Gastown is convention over configuration, it manages the whole runtime, workers picking up work automatically. Ralph Wiggum is a Claude Code plugin that keeps you more in the driver seat. If you want worktree-based parallelism, you have to manage it. HumanLayer’s agent control plane takes yet another angle. More flavors coming this year. I’ve spent the most time with Gastown, so that’s where I’ll focus.
From Craftsman to Factory Floor
Steve Yegge published a chart recently showing eight stages of agentic coding evolution. Stage 1 is near-zero AI. Stage 8 is building your own orchestrator. Most developers I talk to are somewhere between 3 and 5 - agent in the IDE, maybe YOLO mode, starting to let code scroll by without reading every line.
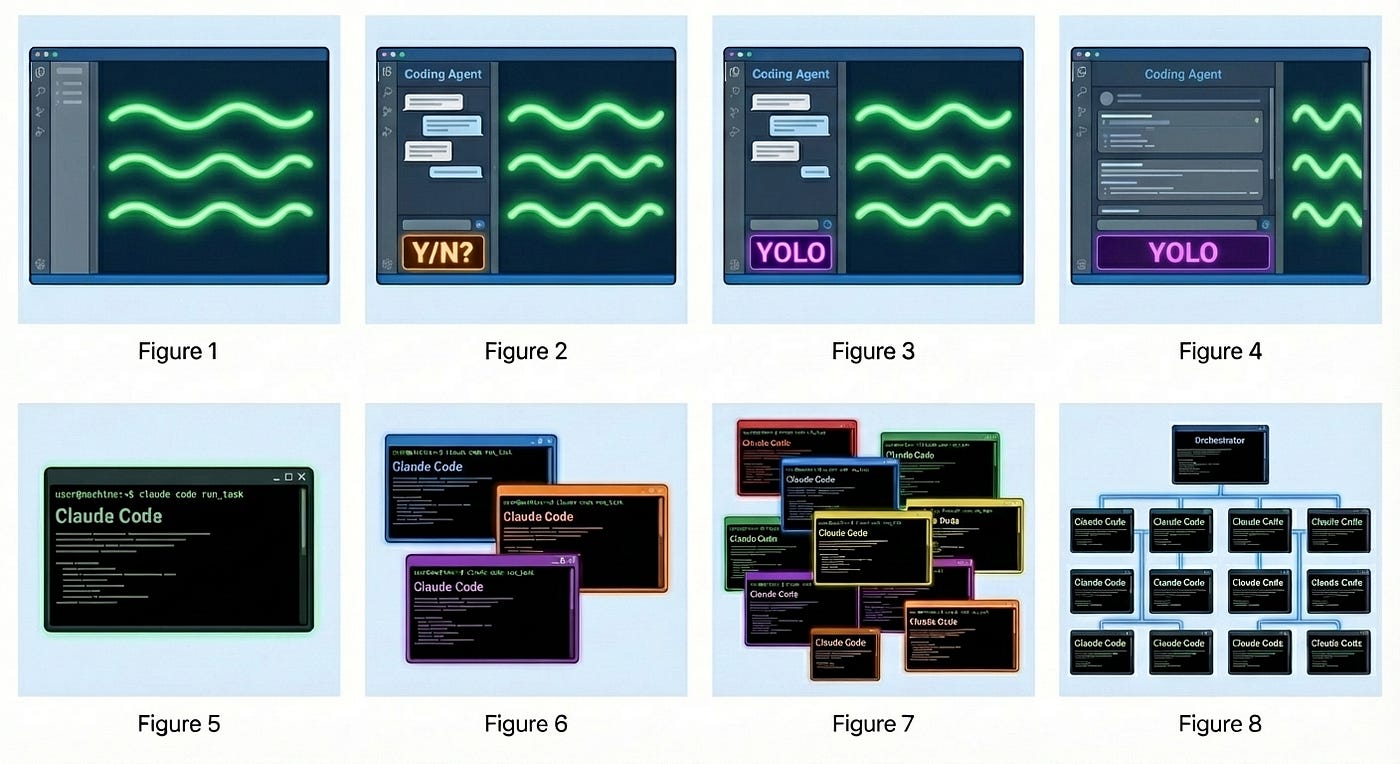
I skipped from 3 to 6. Went straight from IDE-based assistance to multiple CLI agents in parallel. The jump was disorienting.
He’d been trying to get the Model Labs to build this internally half of last year and eventually said “f* it, I’ll do it myself”.
Here’s Yegge’s line that stuck: “They built workers when I’ve built a factory.”
A craftsman works one piece at a time. Deep attention. You know the material, you feel when something’s wrong before you can articulate why. The feedback loop is tight because you’re touching everything.
A factory floor manager operates differently. Work flows through. You’re not touching every piece. You’re watching for exceptions, handling escalations, keeping the line moving. You don’t catch every defect at the source, you catch patterns in the output.
I’ve been a craftsman for twenty years. The factory floor is uncomfortable.
Factory Tolerances
Factories require tolerances that craft production doesn’t.
When you’re the craftsman, you hold inconsistencies in your head. You know a module has weird dependencies. You know not to touch that file without updating the schema. The implicit knowledge lives in your fingers.
Agents don’t have fingers. They have context windows. And when you’re running five in parallel, each has its own context, none containing the tribal knowledge you’ve accumulated over years.
I ran into this hard. I’ve been experimenting with Gastown, Yegge’s multi-agent orchestrator. Had beads, his unit of work, that should have been PR’d already, sitting there. When I finally pushed them, CI failed. Not on hard problems. On stuff any developer would have caught. The agents didn’t know what they didn’t know.
This is what Yegge means by “code hygiene.” Your codebase needs factory tolerances, standardized parts and quality gates that let interchangeable workers produce consistent output.
This includes things not typically defined in CICD, linting and formatting systems. Like when is a PR ready to merge. So far, that has nearly always been a developers decision, and now that will start to change.
What does that mean in practice? Tests that gate correctness, not just coverage. Module boundaries that prevent agents stepping on each other. CI fast enough to give feedback before the next agent builds on broken foundations. Documentation that captures implicit knowledge, not for humans who can ask questions, but for agents who take instructions literally.
All stuff you should have anyway. Now you feel the gaps.
The Bead Problem
Gastown’s unit of work is a bead, backed by Beads, git-based issue tracking designed for agents that forget everything between sessions. The Memento problem. Agents wake up with no memory of ten minutes ago. Beads gives them external memory.
Workers pick up beads from hooks. The principle is GUPP: “If there is work on your hook, you must run it.” Simple propulsion.
The hard part is sizing the units of work. If I’m reflecting the last year of coding with AI, I would say this is what skill developers need to learn.
Too big and agents get lost, burn context on tangents. Too small and you’re drowning in coordination overhead. I don’t have this figured out. After heavy experimentation, I know more about what doesn’t work than what does.
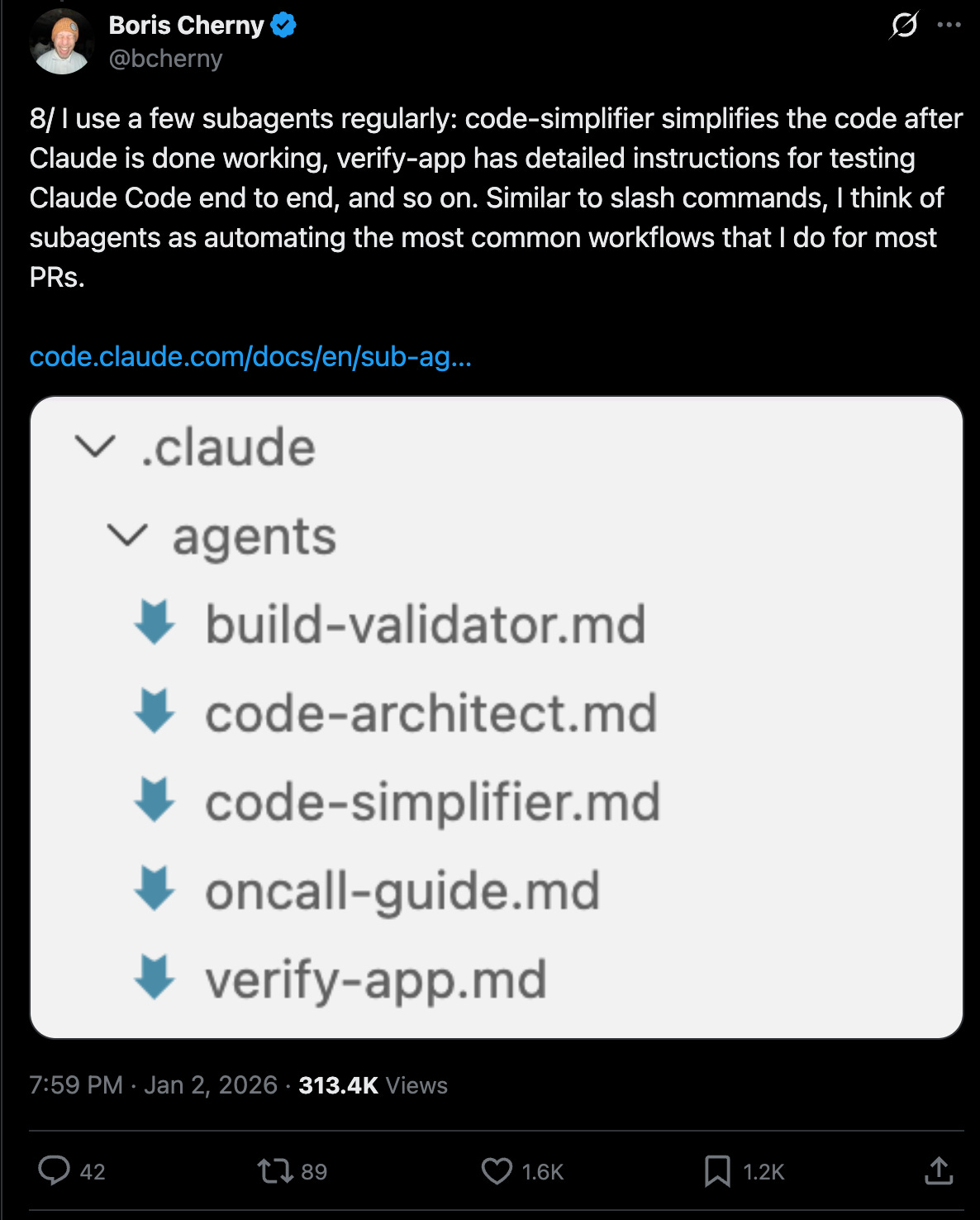
Boris Cherny shared a pattern that helps: subagents for specific workflows. A code-simplifier that reduces output to essential complexity. Agents given a task want to solve it completely, often 10x more code than necessary. The code-simplifier enforces minimum viable change.
Factory workers don’t optimize for elegance. They optimize for consistency and throughput.
Review as Rate Limiter
Here’s where I’m stuck.
Four agents finished work. Each waiting on me. Each needs me to assess: did this change actually do the thing?
That’s the new constraint. Not writing code. Not architecture (though time spent here reduces the rest of implementation and verification problems). Verification at the speed of production.
The old code review model assumed humans wrote the code. You’d read it to understand their thinking, catch errors, suggest improvements. Now the code arrives pre-written. Often more than a human would write, agents handle edge cases I wouldn’t think of, plus edge cases that don’t exist.
The diffs come faster than I can read them. Each one unreviewed blocks the next piece. I flit between instances, all stuck waiting on me. The context switching is taxing. By the time I remember where I was with the third one, the first has lost relevance.
Feature branches help. Maybe stacked diffs would help more. I haven’t solved this. Not sure there’s a solution that doesn’t involve slowing agents or speeding up humans. Both feel like missing the point.
The Team Question
Everything I’ve described is solo work.
What does this look like with 15 developers? I don’t have an answer. My team isn’t ready yet, most are stage 3-4, getting comfortable with agents in the IDE. Jumping them to orchestrated multi-agent workflows would be chaos.
But I think about it. If I’m the bottleneck on review, what happens when everyone is? If codebase hygiene isn’t there for one person, what happens with everyone running parallel experiments?
The monorepo conflicts I hit were partly user error, stacking diffs incorrectly, learning on training wheels. But some was structural. The repo wasn’t built for parallel autonomous work. We didn’t have the code-simplifier (we do now).
Still Going Deeper
The tools keep moving. Gastown is convention over configuration; workers, hooks, an agent coordinating. Ralph Wiggum keeps you more in the driver seat with intentional parallelism. There will be many flavors this year. The patterns are converging even if implementations diverge.
I’m stage 6, moving toward 7. Still using this in personal projects, working out kinks before bringing it to the team.
The open questions I’m sitting with:
When does orchestration complexity cost more than it saves? There’s a minimum scale where this makes sense. I don’t know where the threshold is.
What codebase changes are prerequisites? Factory tolerances sound good. You can’t retrofit twenty years of craft-production assumptions overnight.
How do you train a team when you’re still figuring it out yourself?
The throughput is real. The question is whether you can build the factory floor that survives it.
I’m not sure yet. But I’m not going back to the craftsman bench either.