
Dual Wielding Codex and Claude Code
Compressing Timelines under Pressure

Dual Wielding both Codex and Claude Code is now my favorite go to. Especially when working on both sides of the Shape Up hill.

I’ve only really got vibes to go with on this, but it feels like I’ve done weeks of work in the last 24 hours. We’ve had a pivot on an important client to move from Multi Tenant to a Single Tenant set up.
Ten weeks in one?
How much can CLI code editors impact a large project?
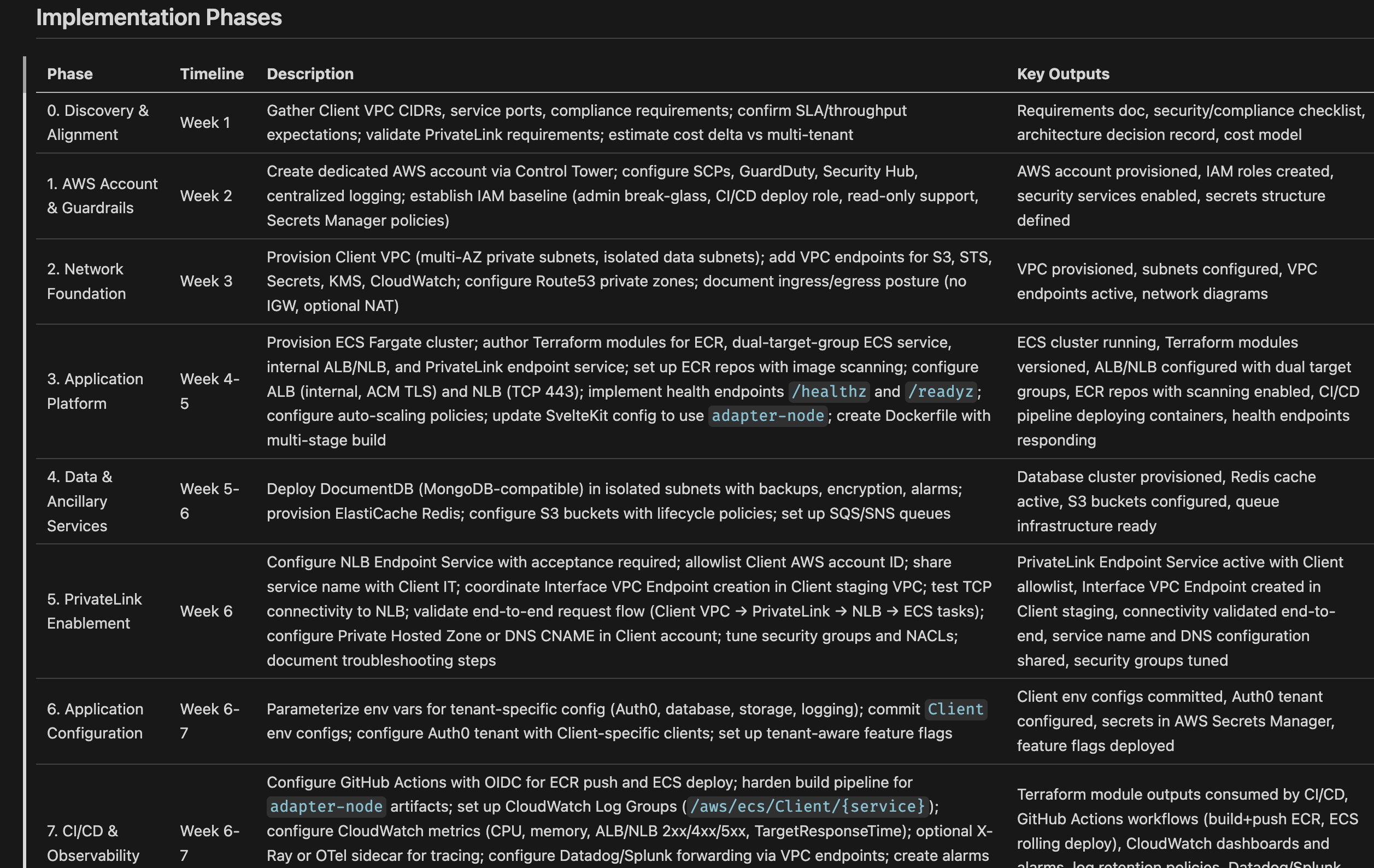
I’ve always laughed at the plans that Claude and GPT come out with for implementation. They feel laughably long so a very conservative estimate is at least half of what they say, but I organized our team around mostly full stack developers so that may just be us. No casting work over walls.
That takes us down to 4 or 5 weeks. Doable with a small team, but there’s still communication overhead. Not everyone on the team has the full picture of our applications. It’s a large surface area. If we included only the devs with the full picture may 2 to 3 weeks.
What if we chose one developer with a bunch of AI minions? The work probably has to look different.
Intermediates are life
I wrote about Ephemeral Software a little while back and part of the ideas came from the use of intermediate files. These are data, PRDs, and functions that are only used only during the process of implementation. They help get you from one state to another in your development lifecycle.
In Conducting Smarter Intelligences than Me, the author discusses conducting multiple LLMs through intermediate files and also jokingly calling themself an intermediate. Essentially this is how I am working and addressing the resumability problem with hitting context windows.
I’ve got 3 types of intermediates for this. The first is the overall vision file. It outlines what our end goal is and links to the implementation file. I sometimes need to update the vision because this whole thing is riddled with N+1 problems.
The implementation file has code examples based on our existing apps and the infra we want to go to. This gets updated frequently as N+1 problems occur. An example is changing the SvelteKit Adapter that puts the project in different deployment contexts like Node, Cloudflare or Vercel. We’re moving from Vercel to Node and we didn’t account for the Node adapter doing additional bundling after Vite bundling. Importantly, this should be updated with a progress tracker after each chunk and ✅ emojis are the cleanest approach I’ve found to work quickly.
And then a worklog file. I started keeping this and its the most optional as you should be tracking in your implementation file. It helps when you hit really tricky dependency trees and have to try several deep options/alternatives.
The actual workflow
So here’s how this actually plays out. I’m inside Cursor the whole time, but I’m switching between Codex and Claude Code depending on where I am on the hill.
When I’m still figuring things out, exploring the problem space or handling changes with many side effects, I’m using Codex. It’s better at handling trees of IFTT, taking a step back and then calling them a forest. It’s hard to describe, it recognizes the higher order patterns better than just addressing the immediate request.
When I know what needs to happen, I switch to Claude Code. This is the execution phase. I point it at the implementation file and say “make these three services match this pattern” and it just goes. I would say it is slightly better at known search, ie I have the symbol of what the problem is and just need to know where to find it. It searches more deeply and steerably than Codex.
The key is that both are working with the same intermediate files. The vision file keeps them pointed at the same goal. The implementation file gets updated as we go, so when I switch tools they both know what’s been done. The worklog captures the weird dependency issues that come up so neither tool steps on the same rake twice.
So why am I still using Cursor at all? Let’s say Claude and Codex get me 95% of the way there, but miss the little nits that its faster to just change manually. That’s the main reason. I tried going back to Code for this and spent about 5 minutes. I also occasionally have Cursor review the changes as a third-party perspective. Claude Code and Codex are the main drivers.
It’s dual wielding in the truest sense. Different tools for different phases of the same work, all inside the same environment, all reading from the same context.
So what’s the actual answer?
Honestly? I don’t know yet. We’re still in the middle of this thing. But what I can tell you is that the velocity feels different. Not just faster, but different in character. It’s less about raw speed and more about being able to hold the entire problem space in your head (or between you and your AI assistants) without the friction of handoffs.
The intermediates are doing the heavy lifting here. They’re the shared context that keeps everything aligned without meetings or Slack threads. When I pick this back up tomorrow, or when I switch from Codex to Claude Code, those files mean I’m not starting from scratch. I’m resuming, not restarting.
Will it actually be ten weeks of work in one? Probably not. But it might be ten weeks in two or three. And more importantly, it might be work that actually ships instead of dying in coordination overhead. That’s the real test.
I’ll keep tracking how this plays out. If it actually compresses ten weeks into two, I’ll write up the post-mortem. If it doesn’t... well, that’s worth writing about too.
The intermediate files approach is good. I've landed in similar territory: a plan document before any agent work, then the CLAUDE.md as the persistent memory that outlives a single session. The Codex for exploration, Claude Code for execution split maps pretty well to what I'd call the plan phase vs the work phase. The bit about "not starting from scratch, just resuming" is the whole point. Documented the formal cycle here: https://reading.sh/compound-engineering-with-ai-the-definitive-guide-05530cf717dd?sk=613e5efd4b161229eee1aba7a7ba1a32